
在数字化办公普及的当下,扫描件PDF已成为企业、机构及个人传递纸质文档的主要形式,无论是合同归档、简历提交还是古籍数字化,扫描件都以其便捷性被广泛应用。但一个普遍存在的痛点的是,扫描件本质上是静态图像文件,未包含可识别的文本编码,导致用户无法直接选中、修改或复制其中内容,极大影响办公效率,甚至耽误重要事务推进。而PDF OCR技术的出现,正是针对性解决这一痛点的核心方案,为扫描件的高效利用提供了全新可能。
PDF OCR(光学字符识别)技术的核心原理,是通过对扫描件图像进行特征提取、图形分析,将图像中的文字、符号转化为可识别、可编辑的数字编码,再按原始文档的版面布局还原文本结构,从而让静态的图像型PDF拥有可编辑属性,实现“图像转文本”的跨越式转化。与传统的格式转换工具不同,PDF OCR无需手动重新录入文字,既能保留原始文档的排版、字体、图片位置,又能快速实现文本的编辑、复制、搜索,从根本上解决了扫描件无法编辑的行业难题。
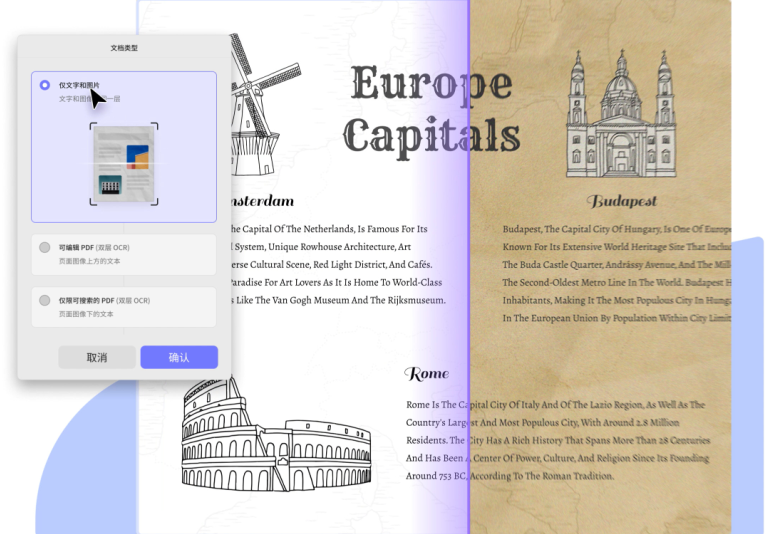
随着技术的迭代升级,PDF OCR工具的实用性不断提升,其中UPDF的OCR功能凭借高效、精准的优势,成为众多用户的优选。UPDF OCR支持一键将扫描文档或图片转换为可编辑、可复制、可搜索的PDF文件,识别准确率最高可达99.59%,能精准还原原始文档的版式布局,避免因识别导致的格式错乱问题。该功能提供3种输出模式,可编辑PDF模式兼顾文件体积与编辑功能,仅文字和图片模式保留原始背景与插图,仅可搜索PDF模式则能最大程度还原原件外观,满足不同用户的场景需求。
同时,UPDF OCR支持38种语言识别,可轻松处理中英文混合文档及多语言文档,用户可通过选择对应语言提升识别准确率,适配跨境办公、多语种资料处理等多元化场景。其操作流程简洁便捷,无需复杂的技术配置,用户打开扫描件后,点击工具栏OCR图标,设置相关参数后即可完成识别,秒级处理速度大幅提升办公效率,无论是个人用户处理零散扫描件,还是企业批量处理合同、票据等资料,都能轻松应对。
在数字化转型加速的今天,高效处理文档已成为提升办公效率的关键。PDF OCR技术打破了扫描件无法编辑的壁垒,而UPDF等具备优质OCR功能的工具,进一步降低了技术使用门槛,让每一份扫描件都能充分发挥价值。未来,随着OCR技术向高精度、智能化、多场景适配方向迭代,将持续助力办公数字化升级,为用户提供更便捷、高效的文档处理解决方案,彻底解决扫描件编辑难题,释放数字化办公的全新潜力。











