

近日,多伦多大学团队推出 REALM 跨模态模型,借助 LoRA 轻量化适配技术打通 RGB 图像与事件流的模态壁垒,高效实现了视觉大模型在事件相机场景下的直接部署与应用。
事件相机通过异步记录像素级亮度变化,在高速运动和极端光照条件下,相比传统 RGB 相机拥有巨大优势;同时这种机制会生成稀疏的 “事件流” 数据。
然而,事件相机面临一个重大瓶颈:数据稀缺。虽然我们有数百万张标记的RGB图像来训练强大的“基础模型”,如视觉Transformer(ViT),但标记的事件数据集很小且罕见。因此,大多数事件处理模型都是任务特定的,并且无法泛化。REALM(RGB和事件对齐的潜在流形)通过将事件数据投影到RGB基础模型预先存在的丰富潜在空间中来解决这个问题。这使得事件相机能够“继承”从数百万张标准图像中学习到的语义和几何知识。
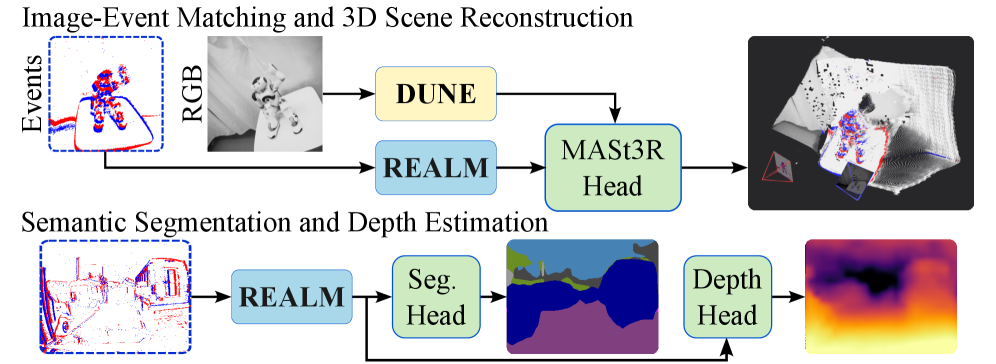
融合RGB和事件数据的核心难点在于“模态鸿沟”。RGB图像是密集的、基于强度的网格,而事件流是稀疏的、时间性的和异步的。现代基础模型,如DUNE,在大规模RGB数据集上训练,以建立对场景的“通用”理解——了解物体在哪里以及它们在几何上如何关联。
以前,研究人员不得不为事件数据从头构建整个架构,这意味着他们无法轻松使用RGB模型发现的强大特征。REALM通过将事件处理问题视为一个对齐任务来改变这一点。如果我们可以将事件流e映射到一个潜在特征向量Z_E,使其看起来像从相应图像x生成的潜在向量Z_I,我们就可以使用为该图像模型已经构建的所有“头部”(预测层)。
REALM 框架建立在 DUNE(一个通用 ViT)之上。DUNE 的编码器由一个嵌入阶段和一个 Transformer 骨干组成。REALM 的目标是找到一个映射,将事件数据转换为特征,使得生成的特征与 DUNE 处理 RGB 图像得到的特征在同一流形空间中对齐。
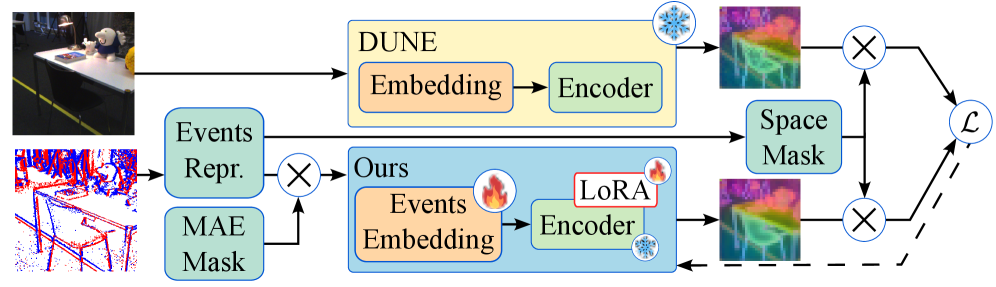
为了使事件数据与为图像设计的Transformer兼容,REALM使用了一个轻量级的卷积主干。该茎将事件体素网格(事件随时间变化的3D表示)转换为补丁token。这些token在结构上与从RGB图像生成的token相同,从而可以将其输入到相同的Transformer骨干中。
为新模态重新训练一个庞大的基础模型计算成本高昂,并且存在 “遗忘” 从 RGB 图像中学到的宝贵知识的风险。REALM 使用 LoRA 来解决这个问题。它不直接更新 Transformer 的原始权重,而是引入了一组可训练的低秩矩阵来生成小幅度的权重更新。这使得模型能够仅使用总模型参数的 10.47% 来适应事件数据,同时保持核心知识库冻结。
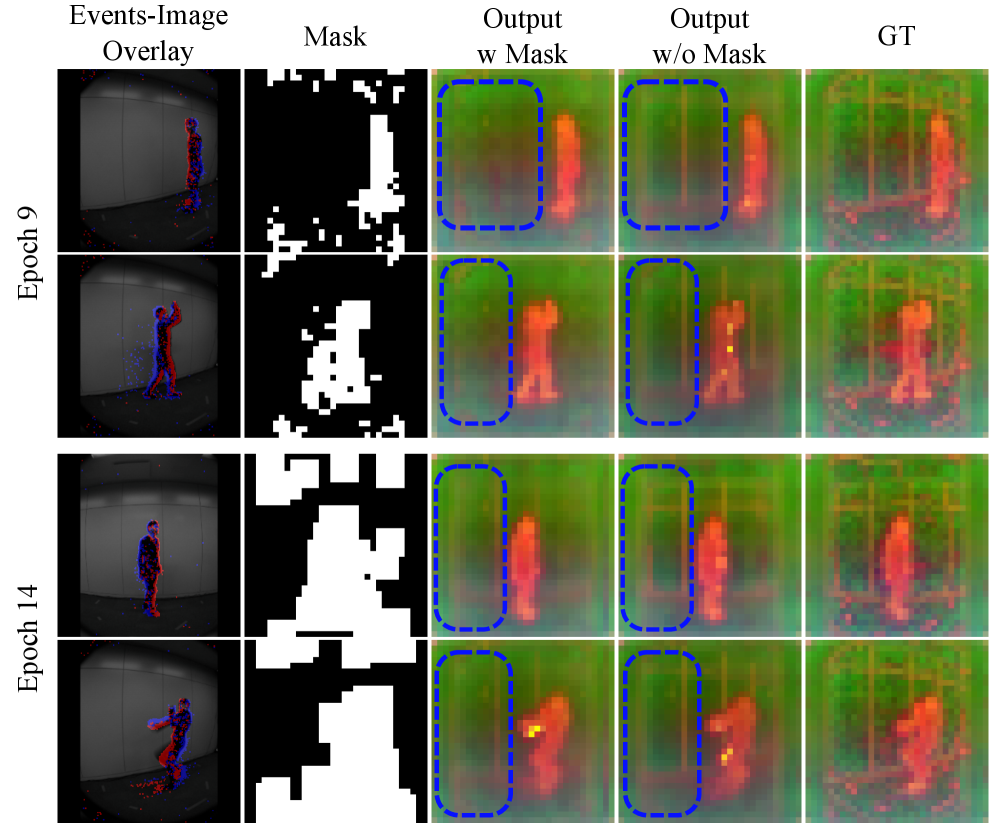
为了确保模型学习到鲁棒的场景表示而不仅仅是复制像素,REALM在训练过程中采用了两种类型的掩码:
渐进式空间蒸馏:
事件数据是稀疏的,通常只有边缘可见。如果模型试图一次性匹配整个 RGB 图像,它可能会对空的背景区域做过度拟合。REALM 使用了一种掩码策略,训练时从围绕事件位置的小范围区域开始监督,并随着训练的进行逐步扩大监督范围。这迫使模型首先关注信息最丰富的区域,避免了背景过拟合的问题。
MAE风格的输入掩码:
受掩码自编码器启发,模型随机丢弃 30% 的输入事件令牌。这迫使适配后的主干网络从不完整、降级的输入中重建出密集的全局理解。
通过结合多种损失进行训练 —— 特别是平衡 L1 距离、余弦相似度和均方误差的总损失 —— 模型学会将事件数据投射到与 RGB 数据完全相同的语义聚类中。
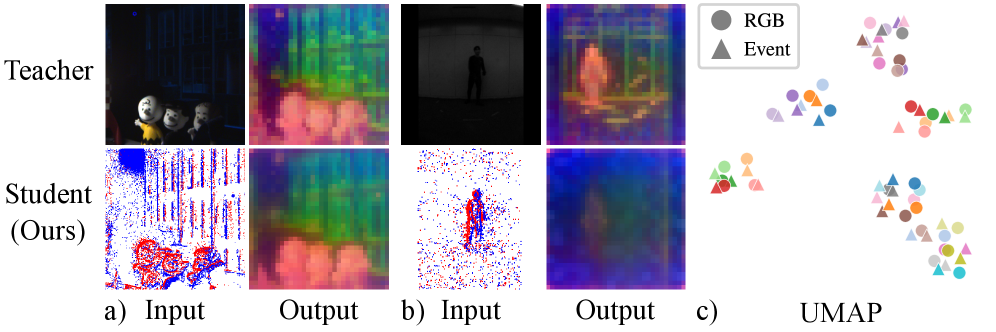
如图3所示,UMAP投影表明,对齐流形成功地将相似对象分组在一起,无论它们是以RGB帧还是异步事件流的形式感知到的。
REALM有效性的最重要证明是“零样本迁移”。这意味着将一个仅在RGB图像上训练的解码器(如深度估计器或分割器)直接应用于REALM的事件特征,而无需对事件进行任何进一步的训练。
在夜间驾驶等挑战性条件下,标准RGB相机常因曝光不足而失效。由于REALM的流形与DUNE的几何先验对齐,它能够比专门的纯事件模型更准确地从事件中估计深度。
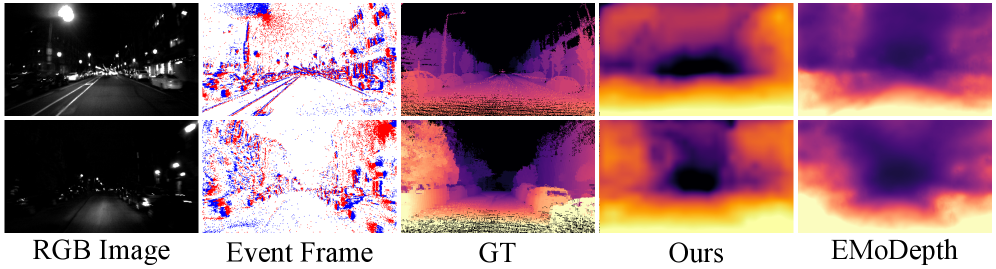
在MVSEC数据集的夜间基准测试中,REALM超越了专门的无监督方法。例如,在“户外夜间1”序列中,REALM的误差低于其自身的RGB教师模型,这表明事件传感器的高动态范围成功保留在对齐流形中。
REALM在DSEC数据集上进行了评估,使用一个在RGB图像上训练的简单线性头将像素分类为11个类别(道路、天空、汽车等)。

尽管事件稀疏,REALM实现了55.37%的平均交并比(mIoU),这与ESS等专门的事件架构具有竞争力。这证明了高级语义类别(例如,区分“人行道”和“道路”)成功地从RGB领域迁移到了事件领域。
也许最令人印象深刻的结果是大基线特征匹配。在两个非常不同的视角之间匹配特征对于机器人技术和测绘至关重要。REALM以完全零样本的方式利用了MASt3R头——一个复杂的几何解码器。
在 ECD 数据集上,REALM 实现了 63.32% 的 AUC@20° 指标,较之前的最优技术(SuperEvent 为 46.7%)有显著提升。它还展现出对旋转的卓越鲁棒性,即使相机视角改变近 100 度,也能保持高精度。
REALM 代表了我们处理非标准传感器方式的范式转变,这一突破为深耕事件相机技术与行业应用的动微视觉,带来了极具实践价值的通用技术范式。REALM 提出,我们无需为每种新型相机(热成像、事件、激光雷达)收集大量新数据集,而是可以简单地将这些传感器 “插入” 到现有 RGB 基础模型的潜在流形中。对动微视觉而言,这意味着事件相机产品无需从零搭建专属模型体系,就能高效复用成熟的视觉大模型能力,大幅降低了工业检测、电网监测、机器人感知等场景的落地成本与周期,也为非标准传感器的规模化应用开辟了全新可能。
从 REALM 所揭示的事件相机接入视觉大模型路径看,动微视觉以全栈自主可控的类脑 DVS 芯片为核心底座,深耕事件驱动型动态视觉技术路线,正在从底层感知架构上打破传统帧式视觉的功耗、延迟与动态范围天花板,并为下一代机器视觉与多模态智能模型的结合提供关键入口。动微视觉已完成从芯片设计、智能相机模组到行业解决方案的全链条布局,产品覆盖车载高阶智驾、工业高精度检测、低功耗智能安防等核心赛道,携手国网、头部车企等标杆客户打造行业落地样板,推动类脑视觉技术从实验室走向千行百业的规模化应用,也为事件视觉与大模型融合后的产业标准和未来方向提供中国方案。











